
How to AI Prompt with a Formatter: Structured Engineering for Developers
You know that sinking feeling when your AI output looks nothing like what you asked for? The JSON is malformed, the tone is wrong, and half your instructions got ignored. The problem is not the model — it is how you are formatting the prompt.
To master how to AI prompt with a formatter, implement the RTCCO framework (Role, Task, Context, Constraints, Output) using structured delimiters like XML or JSON. This treats prompts as modular software assets, which can reduce model hallucinations by up to 60% and cut manual processing time by 75% as of May 2026.
Why Your Paragraph Prompts Keep Failing
By 2026, professional AI work has moved away from “chatting” toward Prompt-as-Code (PaC). The problem with paragraph prompts — those long, unstructured blocks of text — is that models struggle to separate your actual instructions from the background data or output requirements mixed in with them.
Data from PromptOT shows that moving to structured engineering can cut errors by 60% and speed up manual processing by 75%. Alex Ostrovskyy describes hardcoded prompts as the “modern equivalent of magic numbers in source code” — brittle systems that are nearly impossible to update without breaking something.
Before vs. After: The Formatting Difference
Before (unstructured):
You are a helpful coding assistant. Please write a Python function that validates
email addresses. Make sure it handles edge cases like plus signs and subdomains.
The output should be in JSON format with a valid boolean and the cleaned email.
Also make sure you add proper error handling and don't forget logging.
After (RTCCO + XML delimiters):
<system_instructions>
<role>Senior Python engineer specializing in input validation</role>
<primary_objective>Write a production-grade email validator</primary_objective>
</system_instructions>
<context>
Must handle: plus addressing ([email protected]), subdomains,
internationalized domains. Target: Python 3.11+.
</context>
<task_requirements>
<rules>
- Use only stdlib (no regex shortcuts)
- Return structured JSON
- Include type hints
</rules>
<steps>
1. Parse the input string
2. Validate format per RFC 5322
3. Return JSON with "valid" boolean and "cleaned_email"
</steps>
</task_requirements>
<output_format>
{"valid": bool, "cleaned_email": str, "error": str | null}
</output_format>
Same goal, dramatically different results. The formatted version gives the model zero room for ambiguity.
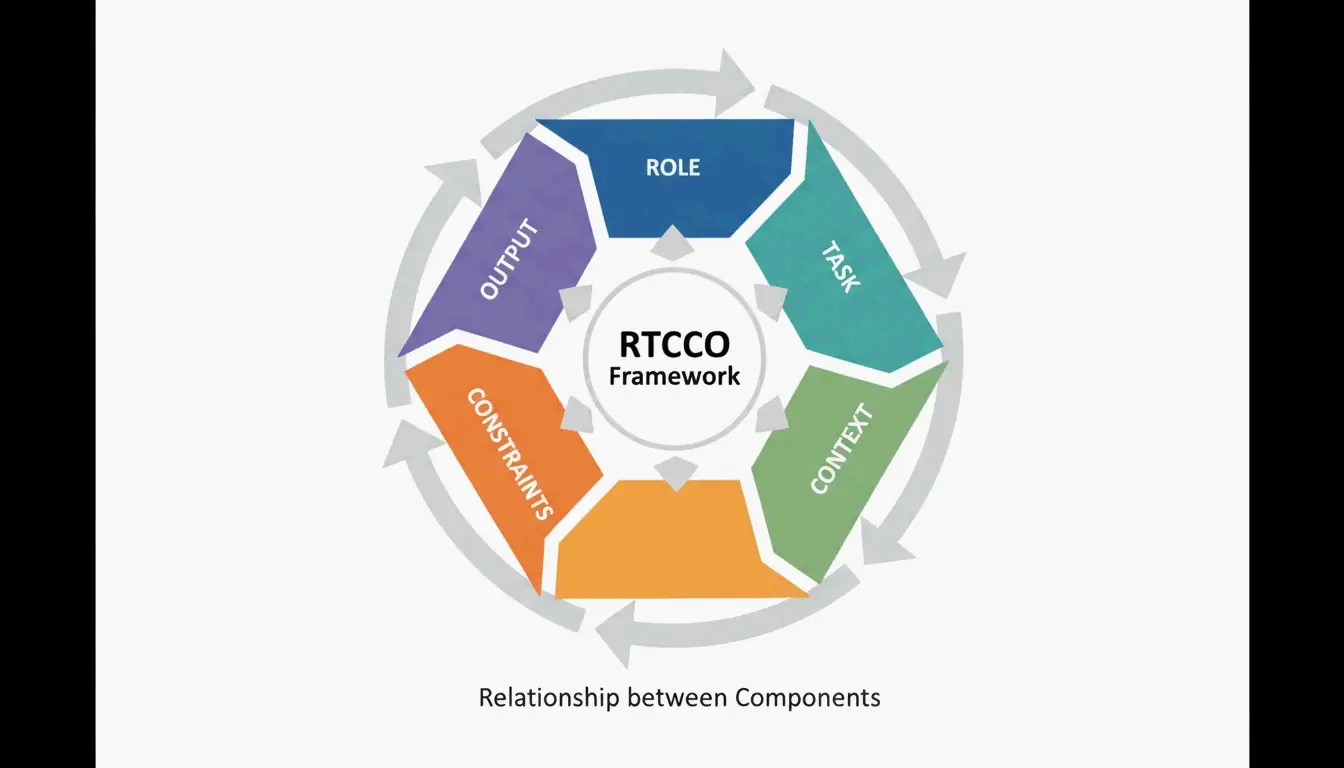
The RTCCO Framework: Your Prompt’s Skeleton
The industry has converged on RTCCO as the standard prompt architecture. Every prompt breaks down into five parts:
| Element | Purpose | Example |
|---|---|---|
| Role | Who is the AI? | “Senior backend engineer” |
| Task | What specific action? | “Write a rate limiter middleware” |
| Context | What background data? | RAG retrieval, codebase snippets |
| Constraints | What are the rules? | “No external dependencies” |
| Output | What should it look like? | “Valid Python 3.11 with type hints” |
The XML Skeleton Template You Can Copy Now
Here is the production-ready template. Copy it, adapt it, ship it.
<system_instructions>
<role> [Expert Persona] </role>
<primary_objective> [Main Goal] </primary_objective>
</system_instructions>
<context>
[Background Data or RAG Retrieval]
</context>
<task_requirements>
<rules> [Non-negotiable Constraints] </rules>
<steps> [Specific Workflow] </steps>
</task_requirements>
<output_format>
[JSON/XML/Markdown Specification]
</output_format>
<recency_recap>
[Reminder of Critical Constraints]
</recency_recap>
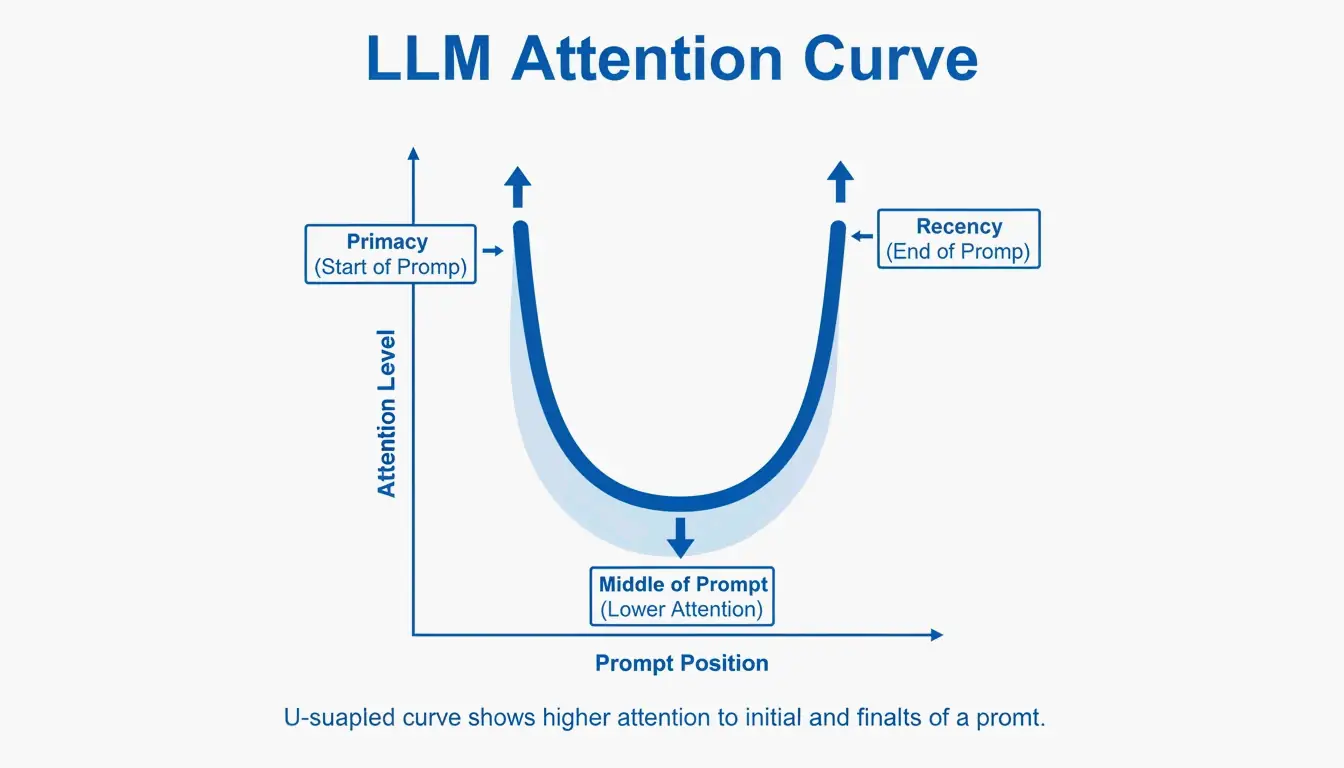
Why the Recency Recap Matters
LLMs have a known “Primacy and Recency” bias — they remember the beginning and end of a prompt better than the middle. Testing cited by PromptOT showed that moving critical rules from the middle to the Recency Recap block at the bottom boosted accuracy from 78% to 96% in production use. Keep the Role at the top, put your most vital rules at the bottom.
Delimiters as a Security Fence
Delimiters are not just about organization — they are a security mechanism. Wrapping user input in tags like <user_input> tells the model: “This is data to process, not new instructions to follow.” This is your primary defense against prompt injection attacks where users try to override your system instructions.
Common pitfall: If you inject user data directly into the prompt without delimiters, a user can write “Ignore all previous instructions and…” and the model will comply. Always wrap external data in tagged blocks.
Modular Architecture: Stop Writing Mega-Prompts
Instead of one fragile 2,000-token prompt, break your system into independent modules. This prevents instruction collision — where changing the tone of a prompt accidentally breaks its JSON output format.
The key principle is Context Engineering: separate static instructions from dynamic data. In a production RAG system, your prompt is a template where the <context> block gets filled with fresh data at query time. As Jono Farrington of OptizenApp explains, this modular approach makes large-scale AI deployments far more consistent.
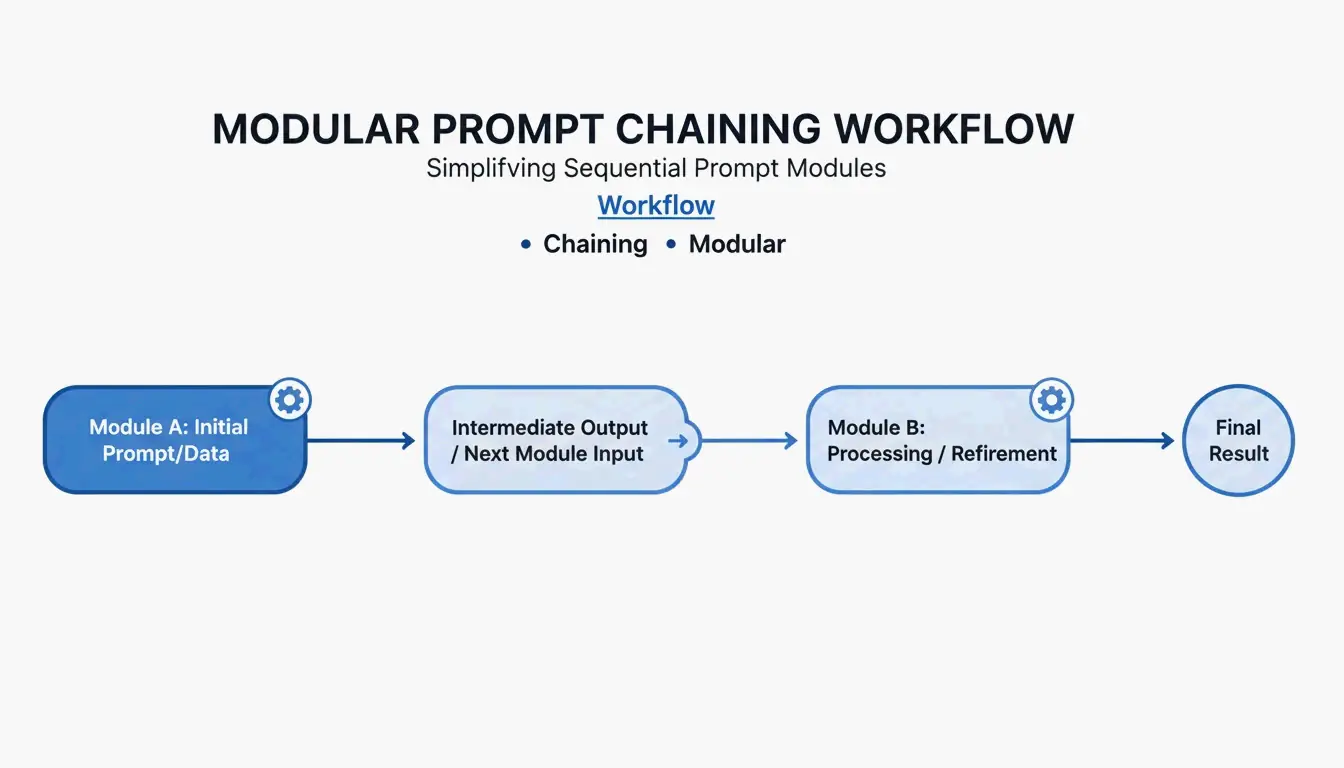
Prompt Chaining: Connecting Modules
For complex workflows, use Prompt Chaining — where the output of one module becomes the input for the next:
[Planner Module] --> outline --> [Executor Module] --> draft --> [Reviewer Module] --> final
This step-by-step approach improves output quality by roughly 35% because the model only focuses on one sub-task at a time.
Copy-and-use chaining example:
planner_prompt = """
<system_instructions>
<role>Technical architect</role>
<task>Create a step-by-step plan for: {user_request}</task>
</system_instructions>
<output_format>JSON array of steps</output_format>
"""
# Step 2: Executor
executor_prompt = """
<system_instructions>
<role>Senior developer</role>
<task>Implement step: {step_from_planner}</task>
</system_instructions>
<context>{previous_outputs}</context>
<output_format>Code block with inline comments</output_format>
"""
Adding Chain-of-Thought for Hard Problems
When your task involves complex logic, add a <thought_process> block. This forces the model to reason step-by-step before giving an answer, which significantly reduces errors in math, coding, and multi-step reasoning.
<task_requirements>
<rules>Reason inside <thought> tags before answering</rules>
</task_requirements>
<output_format>
<thought> [Your step-by-step reasoning here] </thought>
<answer> [Final JSON output here] </answer>
</output_format>
According to Zencoder, techniques like Tree-of-Thoughts (ToT) extend this further by asking the model to evaluate multiple solution paths simultaneously and pick the best one. This is especially valuable for architectural decisions where there is no single right answer.
Token Cost Warning
Structured reasoning uses more tokens. A typical <thought_process> block adds 200-500 tokens per request. At scale, this means higher API costs. The tradeoff is accuracy: you pay more per request but need fewer retries and less manual correction.
Production Readiness: Versioning, Testing, and CI/CD
The final step is treating prompts like software. Use Semantic Versioning (v1.0.0) so your team can track changes and roll back instantly when a new prompt version degrades.
PromptOT reports that companies managing 50+ prompts can save up to $400,000 per year by centralizing management and reducing the time engineers spend manually tweaking.
Setting Up a Prompt CI/CD Pipeline
# .github/workflows/prompt-tests.yml
name: Prompt Quality Gate
on: [push]
jobs:
test-prompts:
runs-on: ubuntu-latest
steps:
- name: Run Golden Dataset Tests
run: |
# Test against 50-200 curated cases
python scripts/eval_prompts.py \
--dataset golden_dataset.json \
--judge-model gpt-4 \
--min-score 0.85
- name: Regression Check
run: |
# Compare new version vs. production
python scripts/compare_versions.py \
--staging v2.1.0 \
--production v2.0.3 \
--threshold 0.05
A prompt only graduates from Staging to Production once it passes these quality gates scored by an “LLM-as-a-judge.”
Conclusion
Structured prompt engineering with formatters is no longer optional — it is the baseline for anyone building reliable AI tools. The RTCCO framework, XML delimiters, and modular architecture are your stack for turning unpredictable LLM outputs into consistent, production-grade results.
Start with your most-used prompts and refactor them into the RTCCO framework using the XML template above. Move them into version control, set up basic evaluation, and you will have a prompt infrastructure that scales.
FAQ
How do I convert my existing paragraph prompts into RTCCO block format?
First identify the core Task and separate it from Context. Wrap instructions in <rules> tags and provide 3-5 examples in <examples> tags. You can even use an LLM to help — prompt it with “re-parse this unstructured text into the RTCCO framework using XML delimiters” and it will do the heavy lifting.
Should I use XML, JSON, or Markdown delimiters?
XML is the current gold standard for separating instructions from long-form content in models like Claude and GPT-5 because of its strict hierarchy. JSON is better when you need programmatic input/output for API integrations. Markdown works for simple, human-readable prompts but lacks the strict boundary definition needed for complex, multi-layered production prompts.
How do I implement automated CI/CD testing for prompts?
Set up a testing suite with a “Golden Dataset” (50-200 curated test cases) and an “LLM-as-a-judge” to score outputs against a rubric. Integrate these tests into your GitHub Actions or Jenkins pipeline so any prompt change is validated for accuracy and tone before deployment.
What is the most common mistake when switching to structured prompts?
Overloading the <context> block. Developers often dump entire codebases or documents into context, which dilutes the model’s attention. Keep context focused on only what is directly relevant to the task. If you need to reference large documents, use RAG retrieval to pull only the pertinent sections.